
Partie 5 · Combien ça coûte et les limites
Rate limits API Claude et tiers d'usage : ce qu'il faut savoir avant ton premier appel
Tu comprendras les 4 tiers d'usage API Claude, les limites RPM, ITPM et OTPM, et comment les augmenter sans casser ta facture.
En une phrase, tu repères ton tier de départ, tu actives le prompt caching pour démultiplier ta capacité, et tu protèges ton code avec un exponential backoff pour ne jamais griller tes limites.
Ton premier appel à l'API Claude (la porte d'entrée qui permet à ton code d'appeler Claude au lieu de passer par le chat) peut planter d'un coup avec une erreur "trop de requêtes", même si ton code est parfait. La raison s'appelle un rate limit, et Anthropic le calibre selon un système de tiers d'usage.
On va décortiquer tout ça avant que tu écrives ta première ligne.
C'est un sujet plus technique que les chapitres précédents. Tu peux le sauter si tu utilises seulement claude.ai.
Tu le liras attentivement si tu prévois d'appeler Claude depuis ton propre code (Python, JavaScript, n8n, Zapier).
En 8 minutes de lecture, tu sauras lire la table des limites officielles, tu sauras quand tu vas heurter une limite, et tu sauras quoi faire dans ce cas. Ce guide s'adresse aux développeurs débutants ou aux indépendants qui veulent automatiser via l'API.
C'est le chapitre 22 d'un manuel complet de 67 chapitres disponible sur claude-pour-les-debutants.fr.
Ce que TU fais dans ce guide tient en 3 actions : tu lis 8 minutes, tu identifies ton tier de départ, tu mets en place les bons réflexes pour ne pas griller tes limites. Ce que ce guide fait : il décode la table officielle, il te donne les chiffres exacts par modèle, il te montre l'astuce du cache pour multiplier ta capacité.
C'est quoi un rate limit
Un rate limit, c'est une borne haute sur le nombre d'appels que tu peux faire à l'API dans un intervalle court.
Tu peux le voir comme un restaurant qui limite combien de personnes peuvent commander à la même minute. Si tu reçois trop de monde en même temps, ta cuisine est saturée.
Le rate limit protège l'infrastructure d'Anthropic, et il garantit que tous les clients reçoivent un service correct.
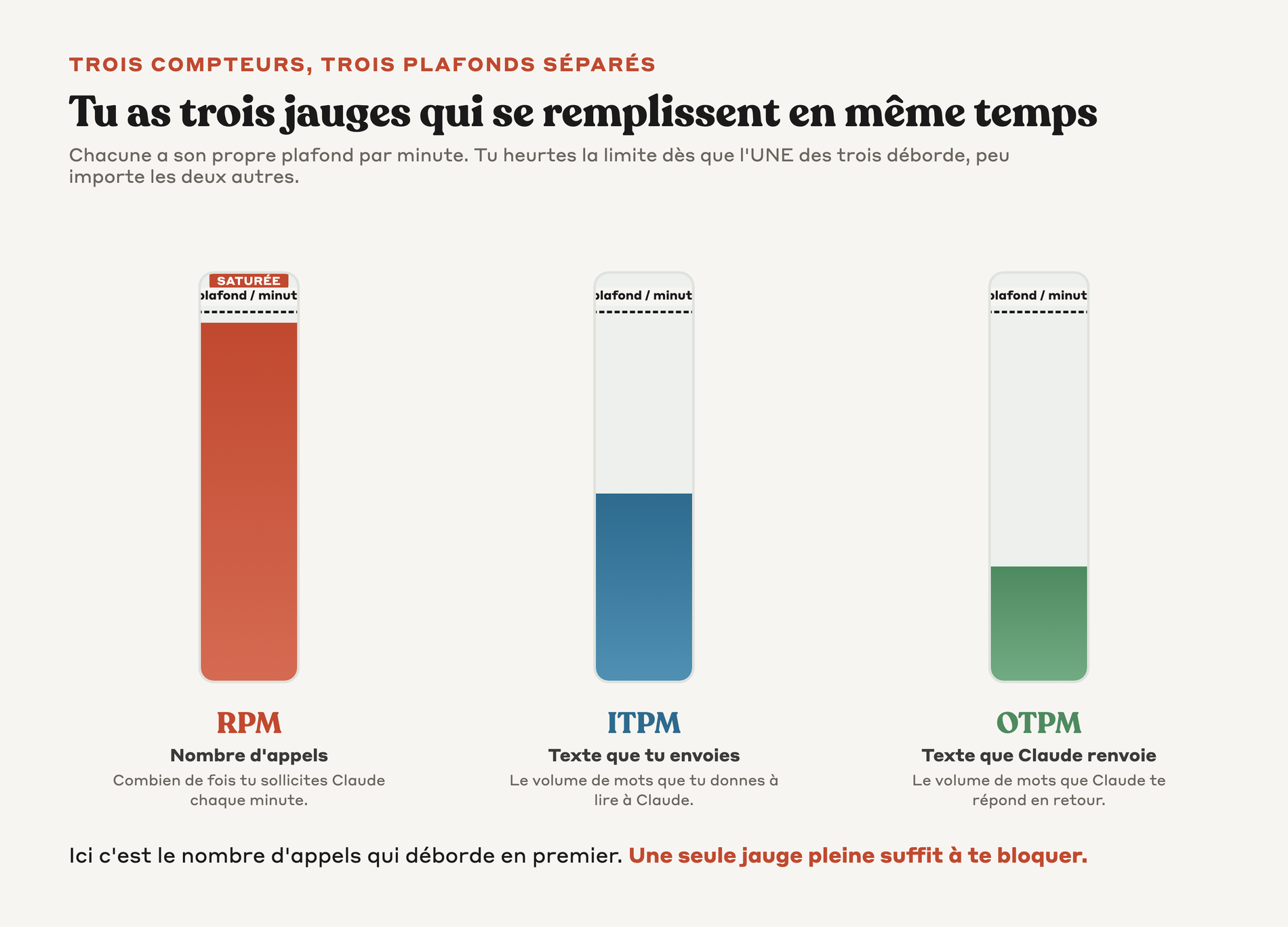
▸ Tu as 3 dimensions de rate limit : RPM (Requests Per Minute, le nombre d'appels par minute), ITPM (Input Tokens Per Minute, le volume de texte que tu envoies par minute) et OTPM (Output Tokens Per Minute, le volume de texte que Claude te renvoie par minute). ▸ Tu peux heurter n'importe laquelle des 3 dimensions en premier selon ton usage. ▸ Tu peux suivre en temps réel ta consommation via les headers HTTP retournés par l'API.
→ Un rate limit n'est pas un quota mensuel, c'est une cadence par minute.
C'est quoi un token
Un token, c'est l'unité de découpe du texte que Claude lit ou produit (une syllabe ou un bout de mot).
En anglais, tu as environ 0,75 mot par token. En français, tu as environ 0,5 mot par token (le français est plus dense en tokens que l'anglais).
Tu peux estimer qu'un message court de 100 mots français équivaut à environ 200 tokens.
▸ Tu peux tester combien de tokens fait ton texte avec le tokenizer officiel sur la Console Anthropic. ▸ Tu paies à l'API en tokens consommés (input + output), pas en messages. ▸ Tu peux réduire ta facture en travaillant en anglais ou en utilisant le prompt caching.
↳ Pour te donner un ordre de grandeur, tu peux compter environ 30 000 tokens pour un PDF de 50 pages en français.
Les 4 tiers d'usage
Sur l'API Claude (c'est-à-dire l'accès programmatique à Claude depuis ton code), tu commences au tier 1 et tu montes automatiquement selon ton usage cumulé.
Voici la table officielle des seuils.
Tier 1 : tu déposes au moins 5 dollars de crédits et ton plafond mensuel est de 500 dollars.
Tier 2 : tu as cumulé 40 dollars d'achats de crédits et ton plafond mensuel reste à 500 dollars.
Tier 3 : tu as cumulé 200 dollars d'achats de crédits et ton plafond mensuel monte à 1000 dollars.
Tier 4 : tu as cumulé 400 dollars d'achats de crédits et ton plafond mensuel monte à 200 000 dollars.
Monthly Invoicing : tu factures à la fin du mois sans plafond, sur dossier négocié avec Anthropic.
☑ L'avancement de tier est automatique. Tu n'as rien à demander, tu déposes les crédits et tu montes au tier suivant.

Les rate limits par tier (Messages API)
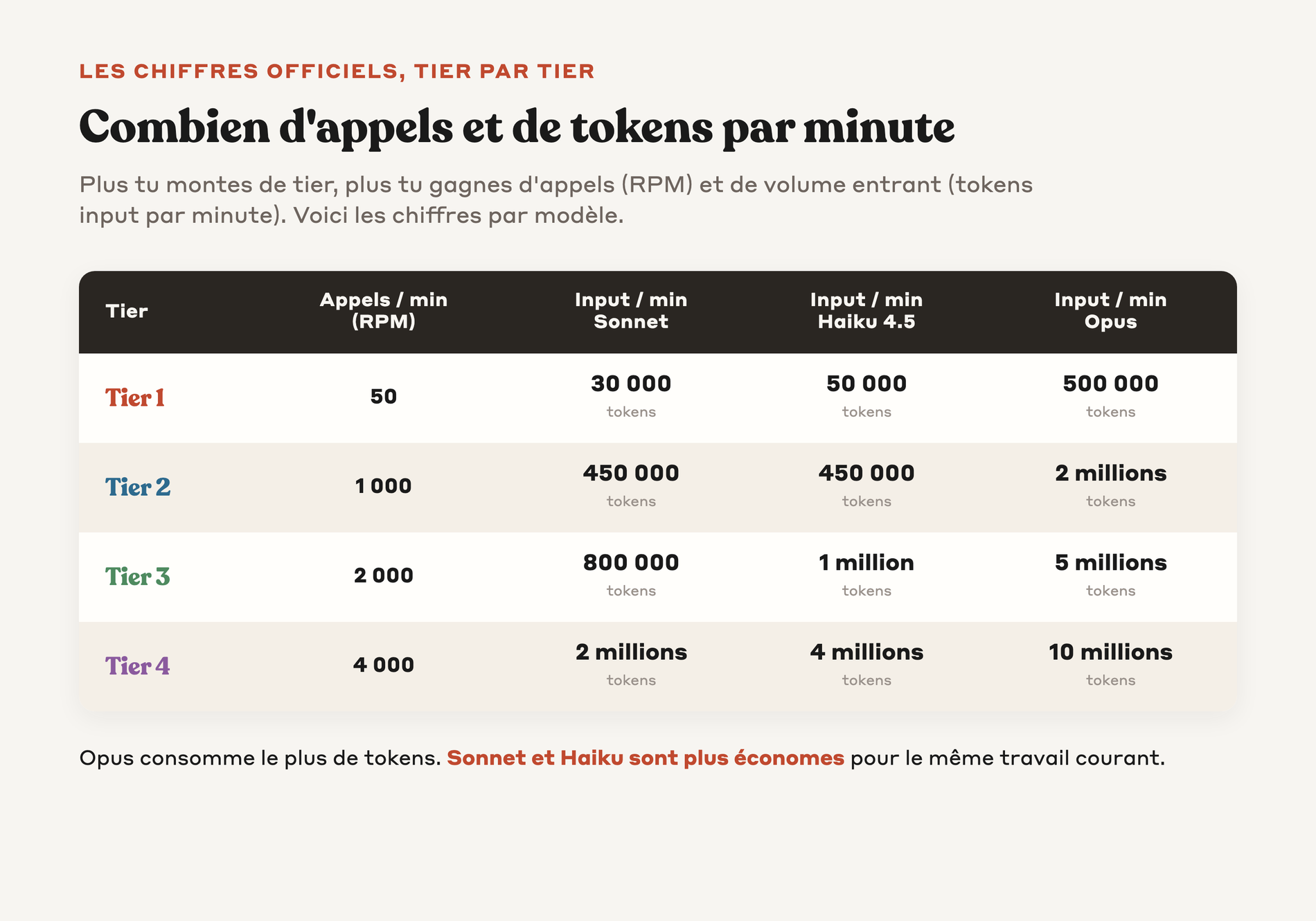
Tu as une table de limites différente pour chaque tier et pour chaque modèle.
Au tier 1, tu es limité à 50 RPM tous modèles confondus. Tu peux envoyer 30 000 tokens (c'est-à-dire des unités de découpe du texte) input par minute sur Sonnet, 50 000 sur Haiku 4.5, et 500 000 sur Opus. Tu peux générer 8 000 tokens output par minute sur Sonnet, 10 000 sur Haiku, et 80 000 sur Opus.
Au tier 2, tu passes à 1 000 RPM. Tu montes à 450 000 tokens input (c'est-à-dire le texte que tu envoies à Claude) par minute sur Sonnet et Haiku 4.5, et à 2 millions sur Opus. Tu peux générer 90 000 tokens output (le texte que Claude te renvoie) par minute sur Sonnet et Haiku, et 200 000 sur Opus.
Au tier 3, tu es à 2 000 RPM. Tu disposes de 800 000 tokens input par minute sur Sonnet, 1 million sur Haiku, et 5 millions sur Opus.
Au tier 4, tu atteins 4 000 RPM. Tu disposes de 2 millions de tokens input par minute sur Sonnet, 4 millions sur Haiku, et 10 millions sur Opus.
▸ Tu peux retrouver la table complète mise à jour sur docs.claude.com/en/api/rate-limits. ▸ Tu as un compteur séparé pour les requêtes (RPM), pour le volume entrée (ITPM) et pour le volume sortie (OTPM). ▸ Tu peux heurter une limite d'un compteur sans toucher les autres.
→ Plus tu utilises Opus, plus tu consommes de tokens. Sonnet et Haiku sont plus économes.
L'astuce du prompt caching
Voici l'astuce qui change tout sur l'API Claude (c'est-à-dire la voie programmatique d'appel à Claude depuis ton code).
Tu peux activer le prompt caching, qui te permet de stocker une partie de ton prompt pour la réutiliser. Les tokens lus depuis le cache ne comptent pas dans ton ITPM sur la plupart des modèles.
Tu démultiplies ta capacité utile sans payer plus cher en limite.
▸ Tu peux concrètement traiter 5 fois plus de tokens si 80 pour cent de ton prompt est en cache.
▸ Tu actives le cache via le paramètre cache_control: {"type": "ephemeral"} sur les blocs de contenu de ton prompt.
▸ Tu paies les tokens écrits dans le cache (cache_creation_input_tokens) mais tu ne paies pas les tokens lus (cache_read_input_tokens).
↳ Tu peux le voir avec un exemple concret. Tu as une limite de 2 millions de tokens input par minute au tier 2 sur Opus. Avec 80 pour cent de cache hit, tu peux processer effectivement 10 millions de tokens input par minute (2M non-cached plus 8M cached).
→ Le prompt caching est l'optimisation #1 à connaître si tu construis une vraie application sur l'API Claude.

Comment tu lis les headers de réponse
À chaque appel API, Claude te renvoie des headers HTTP qui t'indiquent ta consommation en temps réel.
Tu retrouves notamment ces headers utiles dans la réponse.
▸ anthropic-ratelimit-requests-remaining te donne le nombre d'appels restants dans la fenêtre minute.
▸ anthropic-ratelimit-tokens-remaining te donne le nombre de tokens restants (arrondi au millier).
▸ anthropic-ratelimit-requests-reset te donne l'heure exacte de réinitialisation au format RFC 3339.
▸ retry-after apparaît seulement si tu as dépassé une limite et te dit combien de secondes attendre.
import anthropic
client = anthropic.Anthropic()
response = client.messages.with_raw_response.create(
model="claude-sonnet-4-6",
max_tokens=1024,
messages=[{"role": "user", "content": "Bonjour Claude"}]
)
print(response.headers.get("anthropic-ratelimit-requests-remaining"))
print(response.headers.get("anthropic-ratelimit-tokens-remaining"))
→ Tu peux logger ces headers à chaque appel pour suivre ta consommation et alerter avant de heurter le mur.
Que faire quand tu heurtes un rate limit
Quand tu dépasses une limite, l'API (autrement dit le serveur Claude que ton code interroge) te renvoie un code HTTP 429 avec le header retry-after.
Tu as 3 stratégies possibles pour gérer ce cas dans ton code.
Stratégie 1, exponential backoff. Tu attends d'abord 1 seconde, puis 2, puis 4, puis 8, et tu réessayes à chaque fois. Tu reprends le rythme normal quand l'appel passe.
Stratégie 2, file d'attente avec contrôle de débit. Tu utilises une bibliothèque comme tenacity (Python) ou bottleneck (JavaScript) pour cadencer tes appels en dessous de ta limite.
Stratégie 3, message Batches API. Tu envoies les requêtes non-urgentes par lots asynchrones. Tu paies moins cher et tu n'es pas soumis aux mêmes limites RPM.
☑ Tu mets en place la stratégie 1 dès le début, c'est le minimum vital. Tu ajoutes la 2 si tu fais plus de 100 appels par minute. Tu utilises la 3 pour les jobs nocturnes non-urgents.
Un prompt pour estimer tes besoins
Voici un prompt copiable dans claude.ai qui t'aide à dimensionner ton tier de départ en fonction de ton projet.
<role>Tu es un architecte logiciel expert en API LLM qui aide les développeurs
à dimensionner leurs limites d'API et à choisir le bon tier Anthropic.</role>
<context>
Voici mon projet d'utilisation API Claude :
- Type d'application : {CHATBOT / BATCH ANALYSIS / AGENT AUTONOME / AUTRE}
- Nombre d'utilisateurs simultanés prévus : {N}
- Volume moyen d'un appel en tokens input : {ESTIMATION}
- Volume moyen d'un appel en tokens output : {ESTIMATION}
- Pic d'usage attendu : {APPELS PAR MINUTE EN PIC}
- Modèle visé : {OPUS / SONNET / HAIKU}
</context>
<task>
1. Calcule ma consommation théorique en RPM, ITPM et OTPM en pic.
2. Détermine le tier minimum qui couvre mes besoins.
3. Vérifie si le prompt caching pourrait baisser ma consommation effective.
4. Recommande les 3 protections à mettre en place dans mon code (backoff,
queue, batches).
5. Estime mon budget mensuel en dollars selon mon usage.
</task>
<constraints>
Reste factuel sur les limites publiées dans la doc Anthropic.
Si mes estimations d'entrée sont irréalistes, demande une clarification
avant de calculer.
</constraints>
<output_format>
Réponds en 5 sections (Consommation, Tier minimum, Cache potentiel,
Protections code, Budget estimé). Maximum 400 mots.
</output_format>
Exemple rempli pour visualiser le résultat :
Type d'application = CHATBOT
Nombre d'utilisateurs simultanés prévus = 50
Volume moyen d'un appel en tokens input = 2000
Volume moyen d'un appel en tokens output = 500
Pic d'usage attendu = 30 appels par minute
Modèle visé = SONNET
→ Tu obtiens une recommandation chiffrée avec ton tier de départ et les protections à coder dès le jour 1.
Un dernier mot
Le système de rate limits API Claude n'est pas un piège, c'est une infrastructure pensée pour servir des milliers de clients en parallèle. Tu démarres au tier 1 avec 50 RPM, tu montes automatiquement selon ton usage cumulé jusqu'au tier 4 à 4 000 RPM.
Plus tu connais les 3 dimensions (RPM, ITPM, OTPM), plus tu sais où tu vas heurter ta limite. Plus tu actives le prompt caching, plus tu démultiplies ta capacité utile.
Plus tu lis les headers de réponse, plus tu anticipes avant de heurter le mur. Et plus tu protèges ton code avec un exponential backoff et une file d'attente, plus ton application tient en production.
Pour aller plus loin, tu lis la doc officielle sur platform.claude.com/docs/en/api/rate-limits et tu testes ton premier appel via la Console Anthropic.
Questions fréquentes
C'est quoi exactement un rate limit ?
Un rate limit, c'est une borne haute sur le nombre d'appels que tu peux faire à l'API en une minute. Ce n'est pas un quota mensuel, c'est une cadence par minute. Si tu dépasses cette cadence, ton appel plante d'un coup même si ton code est parfait.
Est-ce que je dois demander à passer au tier suivant ?
Non, tu n'as rien à demander. L'avancement de tier est automatique. Tu déposes des crédits, ton usage cumulé monte, et tu passes au tier suivant tout seul.
Le prompt caching, ça sert vraiment à quelque chose pour mes limites ?
Oui, et c'est l'astuce qui change tout. Les tokens lus depuis le cache ne comptent pas dans ta limite d'entrée par minute sur la plupart des modèles. Tu peux concrètement traiter cinq fois plus de tokens quand 80 pour cent de ton prompt est en cache.
Que se passe-t-il quand je heurte une limite ?
L'API te renvoie un code HTTP 429 avec un en-tête retry-after qui te dit combien de secondes attendre. Tu mets en place un exponential backoff dès le début, donc tu attends une seconde, puis deux, puis quatre, et tu réessayes. C'est le minimum vital à coder.
Je ne fais que discuter sur claude.ai, est-ce que ce chapitre me concerne ?
Non, tu peux le sauter si tu utilises seulement claude.ai. Ce chapitre s'adresse à toi seulement si tu prévois d'appeler Claude depuis ton propre code en Python ou JavaScript. Tu le liras attentivement le jour où tu voudras automatiser via l'API.
→ Essaie Claude maintenant : claude.ai
→ Chapitre suivant : Comment payer ton abonnement Claude
Ce chapitre t'a aidé ?
Sois le premier à donner ton avis.