
Partie 11 · Claude qui agit pour toi
Managed Agents Claude, l'infrastructure agentique gérée par Anthropic
Tu sauras ce que sont Dreams, Vaults, Sessions et Environments, et pourquoi cette stack change le passage à l'échelle des agents en production.
En une phrase, si tu construis un produit qui vend un agent IA à des centaines de clients, tu laisses Anthropic gérer pour toi la mémoire, les accès de chaque utilisateur et les espaces de travail isolés grâce à quatre briques (Sessions, Environments, Vaults, Dreams) au lieu de bâtir toute cette infrastructure toi-même.
Quand ton agent IA passe de ton ordinateur à un vrai produit utilisé par des centaines de personnes, tu butes sur des problèmes que ton code ne sait pas régler seul. Pour les absorber, Anthropic a sorti depuis avril 2026 une infrastructure cloud baptisée Managed Agents qui gère pour toi la mémoire long-terme, les accès de chaque utilisateur et les espaces de travail isolés.
En 12 minutes de lecture, tu comprends les 4 primitives qui composent Managed Agents (Dreams, Vaults, Sessions, Environments), tu sais quand chacune sert, et tu vois les exemples de code minimaux pour les appeler. Ce guide s'adresse à toute personne qui construit un produit SaaS basé sur des agents IA et qui se heurte au mur du passage à l'échelle.
Tu lis le chapitre 63 d'un manuel de 67 chapitres disponible sur claude-pour-les-debutants.fr.
Le problème que Managed Agents résout
Pour comprendre pourquoi Anthropic a lancé Managed Agents, tu peux regarder les murs que tu rencontres quand tu mets un agent IA en production multi-utilisateurs.
Premier mur, tu te bats avec la mémoire. Ton agent a besoin d'écrire dans une mémoire pendant qu'il travaille. Au bout de 100 sessions, tu te retrouves avec une mémoire qui a accumulé des doublons, des contradictions, des entrées périmées.
Tu n'as pas d'outil officiel pour la nettoyer.
Deuxième mur, tu te bats avec les credentials. Chaque utilisateur de ton produit a son propre compte Gmail, Slack, Notion. Tu dois stocker ces tokens d'authentification quelque part de sécurisé, les rafraîchir quand ils expirent, et tracer quel agent agit pour quel utilisateur.
Troisième mur, tu te bats avec l'environnement d'exécution. Ton agent a besoin d'exécuter du code, de lire des fichiers, de faire des requêtes. Il a besoin d'un environnement isolé par utilisateur pour ne pas mélanger les données.
Quatrième mur, tu te bats avec l'état entre tours. Ton agent doit garder le contexte d'une conversation longue qui peut durer plusieurs jours. Tu dois sérialiser cet état toi-même, le persister, et le rehydrater.
→ Managed Agents résout ces 4 murs avec 4 primitives correspondantes.

Primitive 1, Sessions
Pour gérer une conversation longue durée avec ton agent, tu peux utiliser une Session.
Une Session est un conteneur stateful qu'Anthropic héberge pour toi. Tu crées la Session une fois, tu y envoies des messages au fur et à mesure, et Anthropic maintient le contexte conversationnel d'un tour à l'autre. Tu n'as pas besoin de stocker et re-envoyer toute l'historique à chaque appel.
✦ Tu peux reprendre une session une semaine plus tard, l'agent retrouve l'état exact.
✦ Tu peux attacher plusieurs ressources à une session (vault, environment, memory store).
✦ Tu peux mettre fin à la session quand le job est terminé pour libérer les ressources.
→ Tu transformes ton client API en un simple porteur de messages, sans gestion d'état.
Primitive 2, Environments
Pour donner à ton agent un bureau virtuel propre dans lequel travailler, tu peux utiliser un Environment.
Un Environment est un template de conteneur que tu configures une fois (image Docker, variables d'environnement, script de setup) et que tu réutilises pour chaque Session. Anthropic spawne le conteneur quand la Session démarre, monte l'environnement, et le détruit à la fin.
▸ Tu peux donner à l'agent l'accès à des outils précis (Python, Node, navigateur).
▸ Tu peux limiter l'accès réseau à une liste blanche de domaines.
▸ Tu peux pré-installer des dépendances via le script de setup.
↳ Tu obtiens un sandbox jetable par utilisateur, sans avoir à gérer ton propre cluster Docker.

Primitive 3, Vaults
Pour gérer les credentials de chaque utilisateur final de ton produit, tu peux utiliser un Vault.
Un Vault est un coffre-fort à credentials par utilisateur que tu remplis une fois avec ses tokens (Slack, Gmail, Linear, etc.) et que tu référencies ensuite par ID au moment de créer une Session. Anthropic stocke les secrets, refresh les tokens OAuth automatiquement, et te donne juste l'ID à passer.
vault = client.beta.vaults.create(
display_name="Alice",
metadata={"external_user_id": "usr_abc123"},
)
bearer_credential = client.beta.vaults.credentials.create(
vault_id=vault.id,
display_name="Linear API key",
auth={
"type": "static_bearer",
"mcp_server_url": "https://mcp.linear.app/mcp",
"token": "lin_api_your_linear_key",
},
)
Tu peux ensuite référencer le vault au moment de créer une session pour cet utilisateur.
session = client.beta.sessions.create(
agent=agent.id,
environment_id=environment.id,
vault_ids=[vault.id],
title="Alice's Slack digest",
)
→ Tu peux passer à l'échelle de 100 000 utilisateurs sans gérer toi-même un secret store.
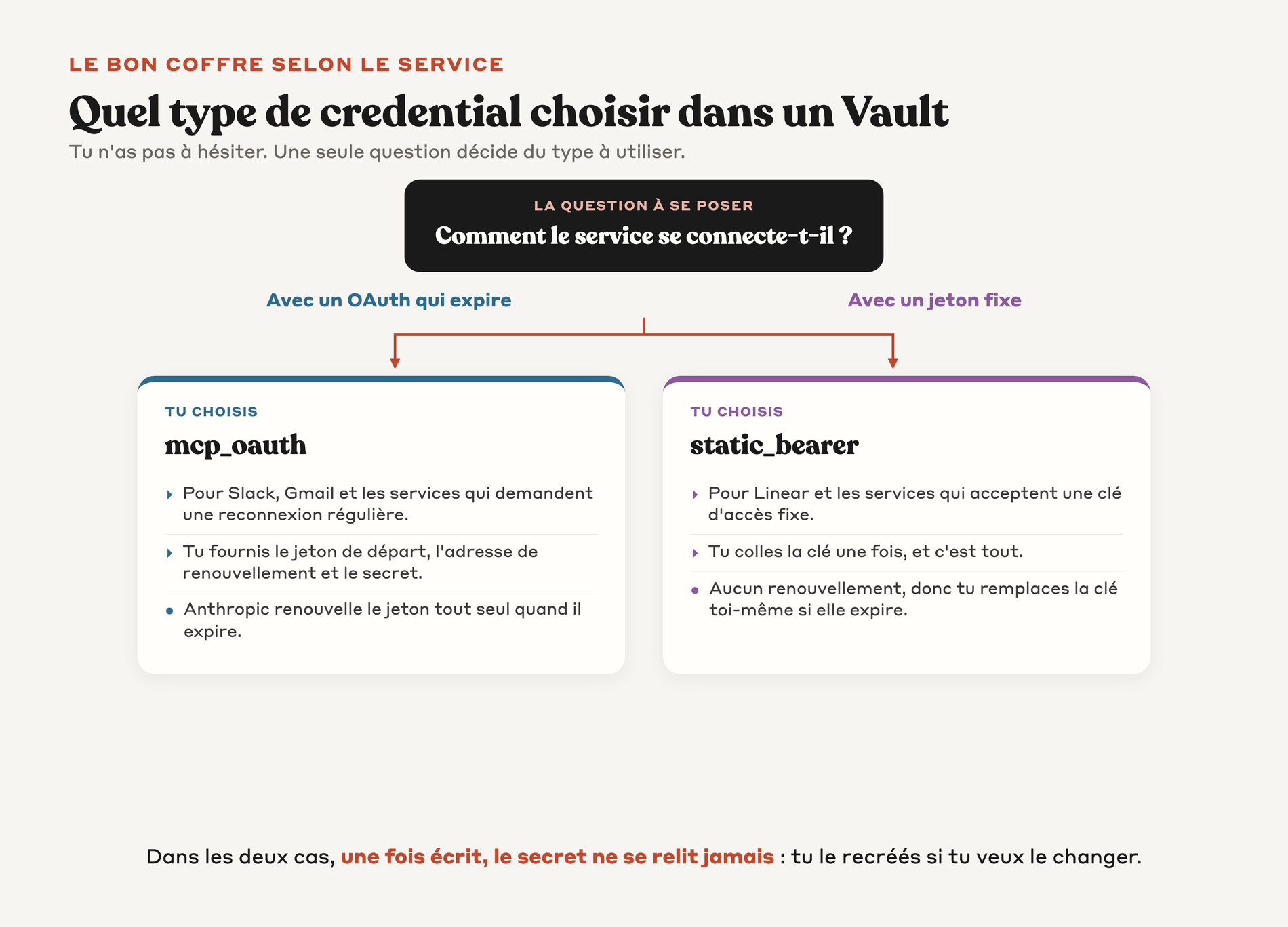
Les 2 types de credentials dans un Vault
Tu disposes de deux types de credentials selon comment le service tiers s'authentifie.
Premier type, mcp_oauth. Tu l'utilises quand le serveur MCP (c'est en gros un connecteur standardisé entre un agent IA et un service externe comme Slack ou Gmail) utilise OAuth 2.0. Tu fournis le token d'accès initial, l'endpoint de refresh, et le client secret. Anthropic refresh le token automatiquement quand il expire.
Deuxième type, static_bearer. Tu l'utilises quand le serveur MCP accepte un token fixe (API key, personal access token). Tu fournis le token et c'est tout. Pas de mécanisme de refresh, donc tu dois mettre à jour le token quand il devient invalide.
↳ Les secrets sont write-only. Tu ne peux jamais les relire après création, même via l'interface de programmation. Tu archives et tu recréés si tu veux changer.
Primitive 4, Dreams
Pour nettoyer la mémoire long-terme de ton agent, tu peux utiliser une Dream.
Une Dream est un job asynchrone qui prend une mémoire existante et une liste de sessions passées, et qui produit une nouvelle mémoire propre. Claude relit tout, fusionne les doublons, remplace les entrées contredictoires par la valeur la plus récente, et fait remonter des nouveaux éclairages.
⚠️ La mémoire d'entrée n'est jamais modifiée. Anthropic produit une mémoire de sortie séparée, tu reviews le résultat, et tu décides de l'utiliser ou de la jeter.
dream = client.beta.dreams.create(
inputs=[
{"type": "memory_store", "memory_store_id": store_id},
{"type": "sessions", "session_ids": [session_a, session_b]},
],
model="claude-opus-4-8",
instructions="Focus on coding-style preferences; ignore one-off debugging notes.",
)
Tu reçois un statut qui passe de pending à running puis à completed (ou failed). Une fois completed, tu récupères l'ID de la nouvelle mémoire dans le champ outputs. Tu peux soit l'attacher aux prochaines sessions, soit l'archiver si elle ne te plaît pas.
Le cycle de vie d'une Dream
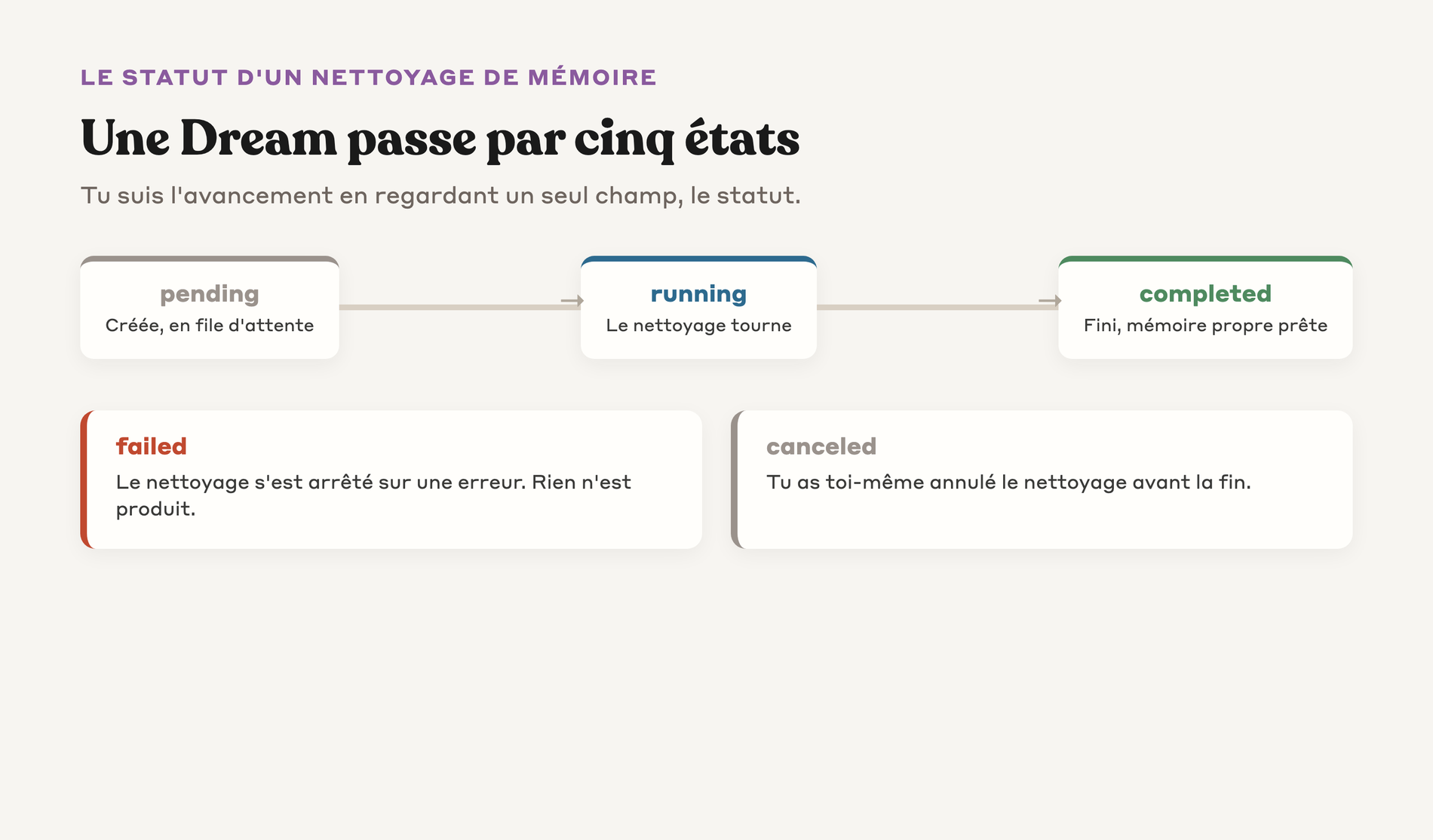
Pour suivre l'avancement d'une Dream, tu peux regarder son champ status.
▸ Quand le statut est pending, la dream est créée et mise en file d'attente.
▸ Quand le statut est running, le pipeline tourne et le champ usage se met à jour à mesure.
▸ Quand le statut est completed, le pipeline a fini avec succès. Tu trouves la nouvelle mémoire dans outputs.
▸ Quand le statut est failed, le pipeline a terminé avec une erreur.
▸ Quand le statut est canceled, tu as toi-même annulé le pipeline.
↳ Le coût d'une dream scale linéairement avec le nombre et la longueur des sessions d'entrée.
Les limites actuelles de Dreams
Tu dois connaître trois limites qui cadrent l'usage.
Première limite, le nombre de sessions par dream. Tu peux passer entre 1 et 100 sessions dans une seule dream. Au-delà, tu fais plusieurs dreams séquentielles.
Deuxième limite, la longueur des instructions. Tu peux écrire jusqu'à 4096 caractères dans le champ instructions qui guide Claude sur ce qu'il doit privilégier.
Troisième limite, tu peux utiliser uniquement trois modèles. Tu choisis claude-opus-4-8, claude-opus-4-7 ou claude-sonnet-4-6 pour le moment.
▸ Anthropic facture les dreams aux tarifs standards de tokens du modèle sélectionné.
Comment combiner les 4 primitives
Pour construire un produit SaaS complet, tu peux combiner les 4 primitives dans un workflow type.
Étape 1, tu crées un Agent (la configuration réutilisable de ton agent) avec son prompt système et ses outils.
Étape 2, tu crées un Environment (le template de conteneur) avec les dépendances pré-installées.
Étape 3, à l'onboarding de chaque nouvel utilisateur, tu crées un Vault à son nom et tu y stockes ses credentials Slack/Gmail/etc.
Étape 4, à chaque conversation, tu crées une Session liée à l'Agent, à l'Environment, au Vault de l'utilisateur, et optionnellement à un Memory Store.
Étape 5, tu envoies les messages à la Session. Anthropic maintient le contexte.
Étape 6, périodiquement (chaque semaine, chaque mois), tu lances une Dream pour nettoyer la mémoire de l'utilisateur.
→ Tu obtiens un produit agent IA scalable à des dizaines de milliers d'utilisateurs sans gérer infrastructure ni secrets.
Les beta headers requis
Tu dois ajouter des beta headers à chaque appel pour activer ces primitives.
curl -s https://api.anthropic.com/v1/dreams \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "anthropic-beta: managed-agents-2026-04-01,dreaming-2026-04-21" \
-H "content-type: application/json" \
-d '{...}'
Tu utilises managed-agents-2026-04-01 pour activer Vaults, Sessions, Environments. Tu ajoutes dreaming-2026-04-21 pour activer Dreams. Les SDKs officiels (Python, TypeScript, etc.) settent ces headers automatiquement, donc tu n'as pas besoin de les écrire à la main si tu utilises un SDK.
Un dernier mot
Managed Agents n'est pas une fonctionnalité pour ceux qui débutent avec l'API Claude (qu'on appelle aussi interface de programmation, c'est le canal qui permet à un programme externe d'envoyer des requêtes à Anthropic).
C'est une stack d'infrastructure pour ceux qui mettent un agent IA en production multi-utilisateurs. Si tu construis juste un script personnel pour automatiser une tâche, tu n'as pas besoin de Vaults ni d'Environments. Si tu construis un SaaS qui vend l'agent IA à des centaines de clients, tu vas hitter les 4 murs (mémoire, credentials, environnement, état), et Managed Agents te fait sauter ces obstacles sans construire toi-même l'infrastructure.
Questions fréquentes
Est-ce que j'ai besoin de Managed Agents si je fais juste un petit script perso ?
Non. Si tu construis juste un script personnel pour automatiser une tâche, tu n'as pas besoin de Vaults ni d'Environments. Cette infrastructure sert quand tu mets un agent IA en production pour des centaines d'utilisateurs et que tu te heurtes aux quatre murs (mémoire, accès, environnement, état).
C'est quoi un Vault exactement et qu'est-ce qu'il garde ?
Un Vault est un coffre-fort qui range les accès d'un utilisateur final de ton produit, par exemple ses jetons Slack, Gmail ou Linear. Tu le remplis une fois, Anthropic stocke les secrets et rafraîchit les jetons OAuth automatiquement, et tu n'as plus qu'à passer son identifiant quand tu crées une Session pour cette personne.
Est-ce que je peux relire un secret après l'avoir mis dans un Vault ?
Non. Les secrets sont en écriture seule, donc tu ne peux jamais les relire après leur création, même via le code. Si tu veux changer un accès, tu archives l'ancien et tu en recréés un nouveau.
À quoi sert une Dream et est-ce que ça touche ma mémoire d'origine ?
Une Dream est une tâche qui tourne en arrière-plan, relit la mémoire de ton agent et les sessions passées, fusionne les doublons et remplace les entrées qui se contredisent par la plus récente. La mémoire d'entrée n'est jamais modifiée, car Anthropic produit une nouvelle mémoire à part que tu vérifies avant de l'utiliser ou de la jeter.
Combien de sessions je peux passer dans une seule Dream ?
Tu peux passer entre 1 et 100 sessions dans une seule Dream. Au-delà, tu lances plusieurs Dreams les unes après les autres.
→ Essaie Claude maintenant : claude.ai
→ Chapitre suivant : Hooks et slash commands Claude Code
Ce chapitre t'a aidé ?
Sois le premier à donner ton avis.